
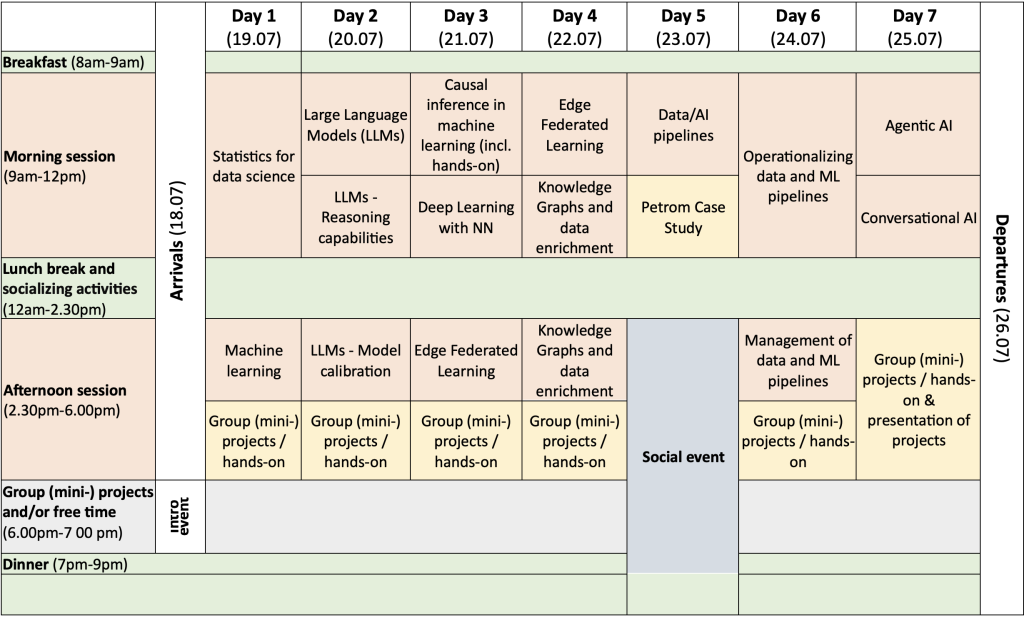
Detailed information about the activities
Statistics for data science (Dan Nicolae)
- Foundations of data analysis
- Statistical inference with resampling methods
- Probability and simulations
Machine learning (Dan Nicolae)
- Linear models and inference
- Model complexity
- Prediction and classification
- Neural networks
Large Language Models (LLMs) – reasoning capabilities and model calibration (Cornelia Caragea)
- Prompting strategies in LLMs – Zero-Shot vs. In-Context Learning
- LLMs reasoning capabilities
- LLMs calibration – do they know what they do not know?
Deep learning with neural networks (incl. hands-on) (Gabriel Terejanu)
- Representation learning
- Deep learning with neural networks
- Implementation in PyTorch
- Regression and gradient descent
- Logistic regression and NNs for non-linear classification
- RNNs for time series prediction
Causal inference in machine learning (incl. hands-on) (Gabriel Terejanu)
- Why do we need causality in data science?
- What is a causal model?
- What is an intervention?
- How to estimate causal effects?
- How to learn a causal model?
Knowledge graphs (Dumitru Roman)
- Intro to graph data structure
- Knowledge Graphs
- Graph data management (graph databases with Noe4j, graph data model, graph construction and querying)
LLMs and Agentic AI (Ioan Toma)
- Introduction to Agentic AI
- Agent Frameworks
Conversational AI (Ioan Toma)
- Conversational AI setup and designing a chatbot interface
- Semantic Knowledge Graphs and their role in Conversational AI
- Building a chatbot using Onlim Conversational AI framework
Edge Federated Learning (Radu Prodan)
- Parallel computing architectures
- Multiprocessing
- Parallel algorithms
- Parallel computing for AI and data science
Data/AI pipelines (Nikolay Nikolov)
- Introduction to data/AI pipelines
- Data/AI pipelines using containers
Operationalizing data and AI pipelines (Wiktor Sowinski-Mydlarz)
- Contemporary data processing
- GATE Institute Data Platform
- Alternatives and decisions
- Pipeline lifecycle
Management of data and AI pipelines (Wiktor Sowinski-Mydlarz)
- Deployment of data and ML pipelines
- Orchestration of data and ML pipelines
- Monitoring of data and ML pipelines
Software (preliminary): Software tools/services to be used during the sessions include:
- Anaconda (https://www.anaconda.com): Installation instructions for various platforms can be found at: https://docs.anaconda.com/anaconda/install
- A number of relevant tools and libraries that we will use can be configured from Anaconda: Python 3, NumPy, SciPy, Matplotlib, Jupyter Notebook, Ipython, Pandas, and Scikit-learn.
- Other Python packages: statsmodels, transformers, lingam
- Onlim Platform (https://app.onlim.com/): Conversational and Knowledge Graph Platform. Accounts can be created https://auth.onlim.com/auth/realms/onlim/login-actions/registration?client_id=onlim&tab_id=gmTCMEh3-6U
- Neo4j (https://neo4j.com): Installation and documentation can be found at https://neo4j.com/developer/get-started.We will use the online sandbox service provided at https://neo4j.com/sandbox, so no installation on local machines is needed for experimenting with Neo4j. Alternatively you can download and install Neo4j Desktop, which provides a convenient way for developers to work with local Neo4j databases (this can be downloaded from https://neo4j.com/download-center/#desktop). We will also use Neo4j Graph Data Science (https://neo4j.com/product/graph-data-science) which comes with Neo4j.
- Docker (https://www.docker.com): An open-source containerization platform that will be used for ML pipelines. Installation instructions can be found at https://docs.docker.com/engine/install.
- SIM-PIPE (https://github.com/DataCloud-project/SIM-PIPE): An open-source tool for dry running of Big Data Pipelines using sample data. The tool allows evaluating pipeline performance and resource requirements at scale. An open version of the tool is available on
.