
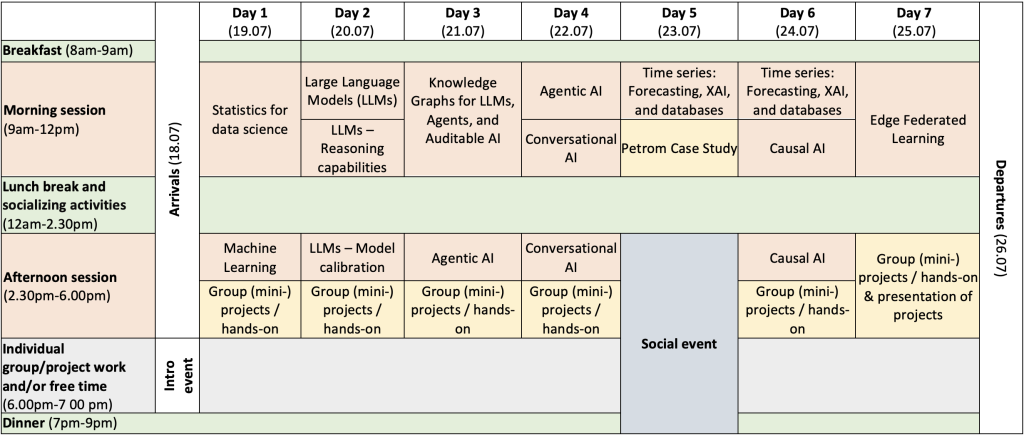
Detailed information about the activities
Statistics for data science (Dan Nicolae)
- Foundations of data analysis
- Statistical inference with resampling methods
- Probability and simulations
Machine learning (Dan Nicolae)
- Linear models and inference
- Model complexity
- Prediction and classification
- Neural networks
Large Language Models (LLMs) – reasoning capabilities and model calibration (Cornelia Caragea)
- Prompting strategies in LLMs – Zero-Shot vs. In-Context Learning
- LLMs reasoning capabilities
- LLMs calibration – do they know what they do not know?
Knowledge Graphs for LLMs, Agents, and Auditable AI (Dumitru Roman)
- From retrieval with LLMs to graphs
- Knowledge graph construction and querying
- Graph algorithms
- Graph-based agent memory and provenance
Agentic AI (Nikolay Nikolov)
- Agent loops and state
- Tool selection and contracts
- Planning, verification and recovery
- Safety, tracing and evaluation
Conversational AI (Ioan Toma)
- Conversational AI setup and designing a chatbot interface
- Semantic Knowledge Graphs and their role in Conversational AI
- Building a chatbot using Onlim Conversational AI framework
Time series: Forecasting, XAI, and databases (Jože Rožanec)
- Using network models to represent and forecast time series
- Introduction to explainability methods
- Introduction to time series databases
Causal AI (Jože Rožanec)
- Introductory concepts
- Causal discovery: time series, LLMs, images
- Applications
Edge Federated Learning (Radu Prodan)
- Distributed and decentralized learning
- Parallel computing for AI workloads
- Federated Learning: concepts, architectures, and challenges
- Communication and privacy in federated systems
- Federated learning on edge devices
- Implementation in Flower
Software (preliminary): Software tools/services to be used during the sessions include:
- Anaconda (https://www.anaconda.com): Installation instructions for various platforms can be found at: https://docs.anaconda.com/anaconda/install
- A number of relevant tools and libraries that we will use can be configured from Anaconda: Python 3, NumPy, SciPy, Matplotlib, Jupyter Notebook, Ipython, Pandas, and Scikit-learn.
- Other Python packages: statsmodels, transformers, lingam
- Onlim Platform (https://app.onlim.com/): Conversational and Knowledge Graph Platform. Accounts can be created https://auth.onlim.com/auth/realms/onlim/login-actions/registration?client_id=onlim&tab_id=gmTCMEh3-6U
- Neo4j (https://neo4j.com): Installation and documentation can be found at https://neo4j.com/developer/get-started.We will use the online sandbox service provided at https://neo4j.com/sandbox, so no installation on local machines is needed for experimenting with Neo4j. Alternatively you can download and install Neo4j Desktop, which provides a convenient way for developers to work with local Neo4j databases (this can be downloaded from https://neo4j.com/download-center/#desktop). We will also use Neo4j Graph Data Science (https://neo4j.com/product/graph-data-science) which comes with Neo4j.
- Docker (https://www.docker.com): An open-source containerization platform that will be used for ML pipelines. Installation instructions can be found at https://docs.docker.com/engine/install.